First step and troubleshooting Docling — RAG with LlamaIndex on my CPU laptop

Motivation
Following my tests with Docling, I wanted to try the “RAG with LLamaIndex” 🦙 functionality. Usually before moving forward and building something on my own, I use a sort of “quick and dirty” application by copy/paste of the sample provided and figure out it if works with my configuration or not.
Building the very 1st basic app (copy/paste of exmaples)
So to begin with “RAG with LLamaIndex”, I followed the instructions from the Docling documentation provided here: https://ds4sd.github.io/docling/examples/rag_llamaindex/
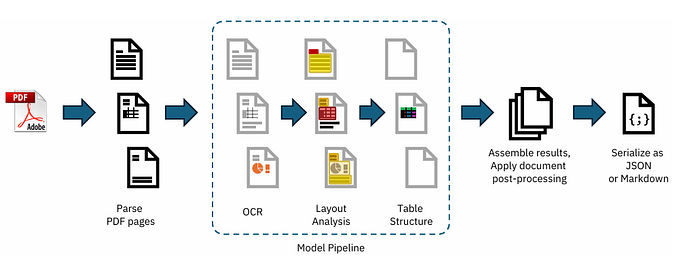
Hereafter the overview of Docling extensions for LLamaIndex.
This example leverages the official LlamaIndex Docling extension.
Presented extensions
DoclingReaderandDoclingNodeParserenable you to:-use various document types in your LLM applications with ease and speed, and
-leverage Docling’s rich format for advanced, document-native grounding.
As in “quick & dirty” I copy/pasted the first 3 parts of samples provided into a main app.py file.
import os
from pathlib import Path
from tempfile import mkdtemp
from warnings import filterwarnings
from dotenv import load_dotenv
# for Tensorflow problem
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '1'
import tensorflow as tf
####
def _get_env_from_colab_or_os(key):
try:
from google.colab import userdata
try:
return userdata.get(key)
except userdata.SecretNotFoundError:
pass
except ImportError:
pass
return os.getenv(key)
load_dotenv()
filterwarnings(action="ignore", category=UserWarning, module="pydantic")
filterwarnings(action="ignore", category=FutureWarning, module="easyocr")
# https://github.com/huggingface/transformers/issues/5486:
os.environ["TOKENIZERS_PARALLELISM"] = "false"
########
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface_api import HuggingFaceInferenceAPI
EMBED_MODEL = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
MILVUS_URI = str(Path(mkdtemp()) / "docling.db")
GEN_MODEL = HuggingFaceInferenceAPI(
token=_get_env_from_colab_or_os("HF_TOKEN"),
model_name="mistralai/Mixtral-8x7B-Instruct-v0.1",
)
SOURCE = "https://arxiv.org/pdf/2408.09869" # Docling Technical Report
QUERY = "Which are the main AI models in Docling?"
embed_dim = len(EMBED_MODEL.get_text_embedding("hi"))
########
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.node_parser import MarkdownNodeParser
from llama_index.readers.docling import DoclingReader
from llama_index.vector_stores.milvus import MilvusVectorStore
reader = DoclingReader()
node_parser = MarkdownNodeParser()
vector_store = MilvusVectorStore(
uri=str(Path(mkdtemp()) / "docling.db"), # or set as needed
dim=embed_dim,
overwrite=True,
)
index = VectorStoreIndex.from_documents(
documents=reader.load_data(SOURCE),
transformations=[node_parser],
storage_context=StorageContext.from_defaults(vector_store=vector_store),
embed_model=EMBED_MODEL,
)
result = index.as_query_engine(llm=GEN_MODEL).query(QUERY)
print(f"Q: {QUERY}\nA: {result.response.strip()}\n\nSources:")
#display([(n.text, n.metadata) for n in result.source_nodes])
print([(n.text, n.metadata) for n in result.source_nodes])I created a .env file with my Huggingface token and sourced it.
HF_TOKEN="hf_xxxxxx"And;
source .env1st run and fail
The first attempt to run the app was unsuccessfull with the following message;
2024-12-16 15:45:13.455420: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.Troubleshooting
A quick search and with the help of stackoverflow I did the following;
conda create --name py11 python==3.11
####
The following packages will be downloaded:
package | build
---------------------------|-----------------
bzip2-1.0.8 | h6c40b1e_6 151 KB
ca-certificates-2024.11.26 | hecd8cb5_0 132 KB
libffi-3.4.4 | hecd8cb5_1 129 KB
openssl-1.1.1w | hca72f7f_0 2.8 MB
pip-24.2 | py311hecd8cb5_0 2.8 MB
python-3.11.0 | h1fd4e5f_3 15.5 MB
setuptools-75.1.0 | py311hecd8cb5_0 2.2 MB
sqlite-3.45.3 | h6c40b1e_0 1.2 MB
tk-8.6.14 | h4d00af3_0 3.4 MB
tzdata-2024b | h04d1e81_0 115 KB
wheel-0.44.0 | py311hecd8cb5_0 150 KB
xz-5.4.6 | h6c40b1e_1 371 KB
zlib-1.2.13 | h4b97444_1 102 KB
------------------------------------------------------------
Total: 29.1 MB
The following NEW packages will be INSTALLED:
bzip2 pkgs/main/osx-64::bzip2-1.0.8-h6c40b1e_6
ca-certificates pkgs/main/osx-64::ca-certificates-2024.11.26-hecd8cb5_0
libffi pkgs/main/osx-64::libffi-3.4.4-hecd8cb5_1
ncurses pkgs/main/osx-64::ncurses-6.4-hcec6c5f_0
openssl pkgs/main/osx-64::openssl-1.1.1w-hca72f7f_0
pip pkgs/main/osx-64::pip-24.2-py311hecd8cb5_0
python pkgs/main/osx-64::python-3.11.0-h1fd4e5f_3
readline pkgs/main/osx-64::readline-8.2-hca72f7f_0
setuptools pkgs/main/osx-64::setuptools-75.1.0-py311hecd8cb5_0
sqlite pkgs/main/osx-64::sqlite-3.45.3-h6c40b1e_0
tk pkgs/main/osx-64::tk-8.6.14-h4d00af3_0
tzdata pkgs/main/noarch::tzdata-2024b-h04d1e81_0
wheel pkgs/main/osx-64::wheel-0.44.0-py311hecd8cb5_0
xz pkgs/main/osx-64::xz-5.4.6-h6c40b1e_1
zlib pkgs/main/osx-64::zlib-1.2.13-h4b97444_1
Proceed ([y]/n)? y
####
conda activate py11
####
conda install tensorflow
### ... some more installations...
conda install keras
✔ took 48s py11 at 15:55:17 ▓▒░
Channels:
- defaults
Platform: osx-64
Collecting package metadata (repodata.json): done
Solving environment: done
# All requested packages already installed.2nd run and success
So I ran again the application as it follows.
python3 app.py
####
Fetching 9 files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 110054.62it/s]
Q: Which are the main AI models in Docling?
A: 1. A layout analysis model, an accurate object-detector for page elements. 2. TableFormer, a state-of-the-art table structure recognition model.
Sources:
[('## 3.2 AI models\n\nAs part of Docling, we initially release two highly capable AI models to the open-source community, which have been developed and published recently by our team. The first model is a layout analysis model, an accurate object-detector for page elements [13]. The second model is TableFormer [12, 9], a state-of-the-art table structure recognition model. We provide the pre-trained weights (hosted on huggingface) and a separate package for the inference code as docling-ibm-models . Both models are also powering the open-access deepsearch-experience, our cloud-native service for knowledge exploration tasks.', {'header_path': '/Docling Technical Report/'}), ("## 5 Applications\n\nThanks to the high-quality, richly structured document conversion achieved by Docling, its output qualifies for numerous downstream applications. For example, Docling can provide a base for detailed enterprise document search, passage retrieval or classification use-cases, or support knowledge extraction pipelines, allowing specific treatment of different structures in the document, such as tables, figures, section structure or references. For popular generative AI application patterns, such as retrieval-augmented generation (RAG), we provide quackling , an open-source package which capitalizes on Docling's feature-rich document output to enable document-native optimized vector embedding and chunking. It plugs in seamlessly with LLM frameworks such as LlamaIndex [8]. Since Docling is fast, stable and cheap to run, it also makes for an excellent choice to build document-derived datasets. With its powerful table structure recognition, it provides significant benefit to automated knowledge-base construction [11, 10]. Docling is also integrated within the open IBM data prep kit [6], which implements scalable data transforms to build large-scale multi-modal training datasets.", {'header_path': '/Docling Technical Report/'})]Conclusion
A nice step for me on my Intel/CPU laptop. I learned how to move forward and execute the very simple examples provided on the Docling documentation site, it’s not rocket science but a first step!
Thanks for reading 🤗.