My first hands-on experience with Docling

TLDR; what is Docling?
Docling, is an open source tool made by IBM research, you can find out all about it on the official GitHub repository: https://github.com/DS4SD/docling.
Just as a reminder, Docling does the following;
- 🗂️ Reads popular document formats (PDF, DOCX, PPTX, XLSX, Images, HTML, AsciiDoc & Markdown) and exports to Markdown and JSON
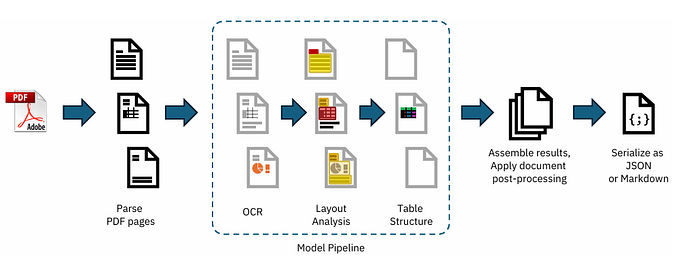
- 📑 Advanced PDF document understanding including page layout, reading order & table structures
- 🧩 Unified, expressive DoclingDocument representation format
- 🤖 Easy integration with 🦙 LlamaIndex & 🦜🔗 LangChain for powerful RAG / QA applications
- 🔍 OCR support for scanned PDFs
Test and first steps with the tool
The very first step is to install Docling on your machine using the “pip” command.
pip install doclingOnce it is done, just make a new folder and start your 1st Python code.
I began with the official documentation page in order to write my sample code: https://ds4sd.github.io/docling/
Testing the Docling installation
Before making any Python code, to test the Docling installation working, you can start with the following bash example.
# Convert a single file to Markdown (default)
docling myfile.pdf
# Convert a single file to Markdown and JSON, without OCR
docling myfile.pdf --to json --to md --no-ocr
# Convert PDF files in input directory to Markdown (default)
docling ./input/dir --from pdf
# Convert PDF and Word files in input directory to Markdown and JSON
docling ./input/dir --from pdf --from docx --to md --to json --output ./scratch
# Convert all supported files in input directory to Markdown, but abort on first error
docling ./input/dir --output ./scratch --abort-on-errorFirst code sample and tests
I used the following sample “Multi-format conversion”; copy/paste to my own directory. As we can notice, in the sample application provided, the links are hard-coded. In order to be able to pick my own files, I used the Python “tkinter” package to use a file selector in the GUI.
The code is provided below. I removed a big part of commented code in order to focus on a very basic test of my own.
import json
import logging
import time
from pathlib import Path
from docling.backend.pypdfium2_backend import PyPdfiumDocumentBackend
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import PdfPipelineOptions
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.models.ocr_mac_model import OcrMacOptions
from docling.models.tesseract_ocr_cli_model import TesseractCliOcrOptions
from docling.models.tesseract_ocr_model import TesseractOcrOptions
## GUI for file selection with thinker
import tkinter as tk
from tkinter import filedialog
## filetypes for thinker dialog box
filetypes = (
('PDF files', '*.PDF'),
('Word file', '*.DOCX'),
('Powerpoint file', '*.PPTX'),
('HTML file', '*.HTML'),
('IMAGE file', '*.PNG'),
('IMAGE file', '*.JPG'),
('IMAGE file', '*.JPEG'),
('IMAGE file', '*.GIF'),
('IMAGE file', '*.BMP'),
('IMAGE file', '*.TIFF'),
('MD file', '*.MD'),
)
_log = logging.getLogger(__name__)
def main():
logging.basicConfig(level=logging.INFO)
# open-file dialog
root = tk.Tk()
filename = tk.filedialog.askopenfilename(
title='Select a file (pdf, pptx, docx, md, img)..',
filetypes=filetypes,
)
root.destroy()
print(filename)
input_doc_path = filename
##
from docling.backend.pypdfium2_backend import PyPdfiumDocumentBackend
from docling.datamodel.base_models import InputFormat
from docling.document_converter import (
DocumentConverter,
PdfFormatOption,
WordFormatOption,
)
from docling.pipeline.simple_pipeline import SimplePipeline
from docling.pipeline.standard_pdf_pipeline import StandardPdfPipeline
# Docling Parse with EasyOCR
# ----------------------
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.table_structure_options.do_cell_matching = True
doc_converter = (
DocumentConverter( # all of the below is optional, has internal defaults.
allowed_formats=[
InputFormat.PDF,
InputFormat.IMAGE,
InputFormat.DOCX,
InputFormat.HTML,
InputFormat.PPTX,
InputFormat.ASCIIDOC,
InputFormat.MD,
], # whitelist formats, non-matching files are ignored.
format_options={
#InputFormat.PDF: PdfFormatOption(
# pipeline_cls=StandardPdfPipeline, backend=PyPdfiumDocumentBackend
#),
#InputFormat.DOCX: WordFormatOption(
# pipeline_cls=SimplePipeline # , backend=MsWordDocumentBackend
#),
InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options),
},
)
)
start_time = time.time()
conv_result = doc_converter.convert(input_doc_path)
end_time = time.time() - start_time
_log.info(f"Document converted in {end_time:.2f} seconds.")
## Export results
output_dir = Path("scratch")
output_dir.mkdir(parents=True, exist_ok=True)
doc_filename = conv_result.input.file.stem
# Export Deep Search document JSON format:
with (output_dir / f"{doc_filename}.json").open("w", encoding="utf-8") as fp:
fp.write(json.dumps(conv_result.document.export_to_dict()))
# Export Text format:
with (output_dir / f"{doc_filename}.txt").open("w", encoding="utf-8") as fp:
fp.write(conv_result.document.export_to_text())
# Export Markdown format:
with (output_dir / f"{doc_filename}.md").open("w", encoding="utf-8") as fp:
fp.write(conv_result.document.export_to_markdown())
# Export Document Tags format:
with (output_dir / f"{doc_filename}.doctags").open("w", encoding="utf-8") as fp:
fp.write(conv_result.document.export_to_document_tokens())
if __name__ == "__main__":
main()Execution and output of the first run on a PDF file;

python aam-custom-convert.py
~/Devs/docling_test python aam-custom-convert.py ✔ base at 16:22:42 ▓▒░
2024-12-03 16:22:58.300 Python[17791:2731022] +[IMKClient subclass]: chose IMKClient_Modern
2024-12-03 16:22:58.856 Python[17791:2731022] The class 'NSOpenPanel' overrides the method identifier. This method is implemented by class 'NSWindow'
/Users/alainairom/Docling_test/mobicheckin_server_event_guest_category_66968af1fc394000725041be_badge_template_66a37cdae369f921e572e4fa_1732039981_NZYRUCY.pdf
INFO:docling.document_converter:Going to convert document batch...
Fetching 9 files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 27373.99it/s]
INFO:docling.pipeline.base_pipeline:Processing document mobicheckin_server_event_guest_category_66968af1fc394000725041be_badge_template_66a37cdae369f921e572e4fa_1732039981_NZYRUCY.pdf
INFO:docling.document_converter:Finished converting document mobicheckin_server_event_guest_category_66968af1fc394000725041be_badge_template_66a37cdae369f921e572e4fa_1732039981_NZYRUCY.pdf in 11.70 sec.
INFO:__main__:Document converted in 11.70 seconds.Execution and output of the first run on an image;

~/Devs/docling_test python aam-custom-convert.py
✔ took 58s base at 16:23:51 ▓▒░
2024-12-03 16:26:01.060 Python[17885:2735156] +[IMKClient subclass]: chose IMKClient_Modern
2024-12-03 16:26:01.607 Python[17885:2735156] The class 'NSOpenPanel' overrides the method identifier. This method is implemented by class 'NSWindow'
/Users/alainairom/Docling_test/Screenshot at Dec 02 08-11-28.png
INFO:docling.document_converter:Going to convert document batch...
Fetching 9 files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 33614.19it/s]
INFO:docling.pipeline.base_pipeline:Processing document Screenshot at Dec 02 08-11-28.png
INFO:docling.document_converter:Finished converting document Screenshot at Dec 02 08-11-28.png in 16.51 sec.
INFO:__main__:Document converted in 16.51 seconds.The output is available as the Python app has defined in the “scratch” directory.

Hereafter the JSON output (and beautified) from the image file processing.
{
"schema_name": "DoclingDocument",
"version": "1.0.0",
"name": "Screenshot at Dec 02 08-11-28",
"origin": {
"mimetype": "application/pdf",
"binary_hash": 10790376354737789131,
"filename": "Screenshot at Dec 02 08-11-28.png"
},
"furniture": {
"self_ref": "#/furniture",
"children": [],
"name": "_root_",
"label": "unspecified"
},
"body": {
"self_ref": "#/body",
"children": [
{
"$ref": "#/pictures/0"
}
],
"name": "_root_",
"label": "unspecified"
},
"groups": [],
"texts": [],
"pictures": [
{
"self_ref": "#/pictures/0",
"parent": {
"$ref": "#/body"
},
"children": [],
"label": "picture",
"prov": [
{
"page_no": 1,
"bbox": {
"l": 121.97575378417969,
"t": 1359.943115234375,
"r": 2361.541015625,
"b": 47.3934326171875,
"coord_origin": "BOTTOMLEFT"
},
"charspan": [
0,
0
]
}
],
"captions": [],
"references": [],
"footnotes": [],
"annotations": []
}
],
"tables": [],
"key_value_items": [],
"pages": {
"1": {
"size": {
"width": 2464.0,
"height": 1420.0
},
"page_no": 1
}
}
}Conclusion
This document describes the very basic Docling usage. I’m going to do some more in depth experiences… so stay tuned 😎
Useful links
- Docling repository: https://github.com/DS4SD/docling
- Docling documentation: https://ds4sd.github.io/docling/